*با سلام و درود به مهمانان عزیز و کاربران گرامی وبلاگ #مهرزاد، ضمن عرض ادب و احترام به شما، این صفحه به منظور اطلاع رسانی و برای نشر آگاهی و غنی سازی می باشد،
خواهشمند است، هر گونه پیشنهاد یا انتقاد را به مدیر سایت بفرمایید.
کلان داده یا دادههای عظیم، به مجموعه دادههای بسیار بزرگ و پیچیدهای اطلاق میشود که ابزارهای سنتی نمیتوانند، آنها را در چارچوب زمانی قابلقبول یا با هزینههای معقول، پردازش کنند.
تأمین سختافزار مورد نیاز، برای جستجو، ذخیره و تجزیهوتحلیل داده، برخی از چالشهای مدیریت کلان داده، با استفاده از ابزارهای سنتی میباشند، که با ابزارهای مدیریت توزیعشده، میتوان بر این چالشها پیروز شد.
امروزه یک مجموعه غنی از ابزارهای پردازش کلان داده، برای کمک به برآورده ساختن تمام نیازهای دادههای عظیم، قابل دسترس است.
در این کتاب، به بررسی پلتفرم قدرتمند هادوپ، که توسط بنیاد نرمافزار آپاچی، طراحی شدهاست، پرداختهایم. این پلتفرم، مجموعهی گستردهای از ابزارها را برای بسیاری از عملکردهای کلان داده ارائه میدهد.
هادوپ، با جاوا نوشتهشده و تحت مجوز آپاچی است و بهعنوان یک سیستم توزیع شده و پردازش موازی کلان داده، توسط شرکت آپاچی، گسترش یافت.
بنیاد نرمافزاری آپاچی، ای اس اف، با رویکرد متن باز برای توسعه نرمافزار، تأثیر بسزایی هم در توسعهی نرمافزار برای کلان داده و هم در رویکرد کلی حاکم بر این رشته دارد.
همچنین ایدهها و توسعه شرکتهای درگیر با کلان داده مانند گوگل و فیسبوک و لینکدین را هم تغذیه میکند.
آپاچی یک برنامه انکوباتور دارد که پروژهها در آن، وارد و بالغ میشوند، تا اطمینان حاصل شود، بهاندازهی کافی، قدرتمند بوده و ارزش تولید دارند.
با این فرض که، احتمال شکست، همواره وجود خواهد داشت، بهگونهای طراحیشده که، قابلیت توسعه در حوزه سختافزار و داده ها را با هم ارائه کند.
در ادامه ابزارهای هادوپ را که به بهترین شکل نیازهای فوق را برآورده میکند، بررسی میکنیم.
اصطلاح کلان داده، معمولاً به دادههایی اطلاق میشود، که فراتر از توانایی محاسباتی ابزارهای سنتی بوده و معمولاً در محدوده چند ده ترابایت و بیشتر هستند، با این حال بالا بودن حجم داده، تنها راه شناسایی کلان داده نیست.
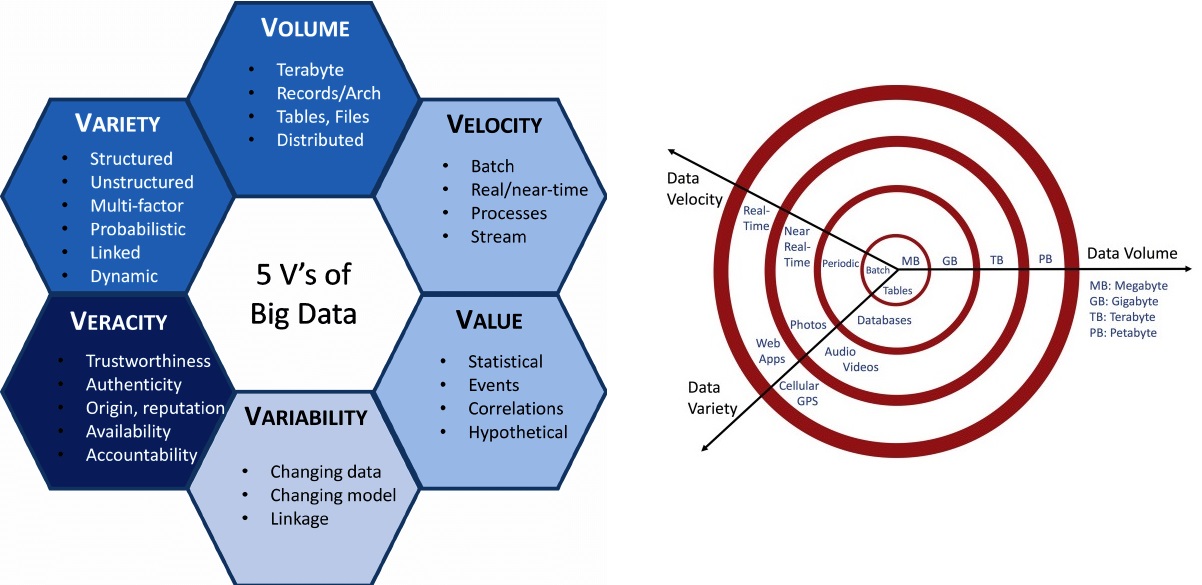
کلان داده، عمدتاً تحت سه واژه ,Volume ,Velocity Variety شناخته میشود. این سه واژه بهاختصار 3V نامیده میشوند. توصیف این سه واژه بهصورت زیر است:
, Volume اندازه و حجم کلی مجموعه داده
, Velocity نرخ تغییر داده و سرعت موردنیاز برای پردازش آن
, Variety وضعیت تنوع ساختار دادهها از لحاظ محتوا و مقدار دادههای، اصوات، تصاویر، سنسور، متن و دادههای بدون ساختار
در تعریف دیگری از کلان داده، دو معیار دیگر یا به عبارتی دو V دیگر نیز، به مفهوم کلان داده، اضافه شدهاست، که عبارتند از :
, Veracity دادهها از لحاظ صحت و دقت نیاز به بررسی و درنتیجه پاکسازی دارند.
, Value نگهداری داده، دارای هزینه است. یعنی هزینه سختافزار، ذخیرهسازی، اما با فروش و تحلیل دادهها میتوان به منفعت و درآمد رسید.
در دنیای واقعی، نمونههای بسیاری از پروژههای کلان داده، در صنایع متعدد وجود دارد. خصوصیات کلان داده باعث میشود که تصویرسازی و گزارش از دادهها یک چالش عمده به حساب آید. هدف از مصورسازی داده این است که اطلاعات واضح و کارآمدی از طریق نمودارهای آماری و گرافیکی و ... استخراج گردد.
کلان داده، باید از نقطه نظر نحوه تغییر یا پردازش محتوا، مورد توجه قرار گیرد. اندازهی مجموعهی دادهها، میتواند بر فرآیندهایی، نظیر ذخیرهی داده، جابجایی، پردازش، نمایش، گزارش و تجزیهوتحلیل، تأثیر گزار باشد.
ابزارهای سنتی، بهسرعت میتوانند، توسط حجم داده، دچار چالش شوند. زمان بازیابی داده یا مدتزمان لازم برای دسترسی به داده با حجم داده، دارای ارتباط مستقیم است.
فرض کنید، بخواهید یک پرسوجوی فوری و ضروری را در مجموعه بزرگی از دادهها، اجرا کنید. ازآنجاییکه یک سیستم بزرگ ذخیره داده، یک انباره داده نیست، نمیتوان انتظار داشت که پاسخ پرسوجوی خود را در عرض چند ثانیه، دریافت کنید، اما بااینحال، راههای مختلفی، برای غلبه بر این چالش وجود دارد.
حذف بخشی از داده، برای کاهش حجم آن میتواند یکی از راهکارهای حل مشکلات ناشی از بزرگ بودن دادهها باشد، اما این راهحل همیشه عملی نیست.
ممکن است، در سازمان، مقرراتی برای ذخیرهسازی داده وجود داشته باشد.
بهعنوان مثال، نگهداری چندساله یا همیشگی دادهها،
افزونبراین، شاید دادههای تجاری ذخیرهشده در آینده بتوانند با خود منافعی را بههمراه داشته باشند. که اگر بخشی از داده، حذف شود، جزئیات از بین رفته و به طبع آن، بسیاری از منافع رقابتی و بالقوه آینده نیز از بین خواهد رفت.
در مقابل راهحل حذف داده، رویکرد پردازش موازی میتواند، ترفند خوبی باشد.
این موازیسازی، مبتنی بر تقسیم است. در این نظریه، دادهها به مجموعههای کوچکتر تقسیم شده و بهصورت موازی پردازش میشوند.
برای پیادهسازی چنین محیطی، ملزوماتی نیاز است. ازآنجایی که رشد داده، منجر به اختلال در پردازش میشود، برای شروع، نیاز به یک پلتفرم ذخیره سازی قدرتمند که قابلیت توسعه پذیری با هزینههای معقول را داشته باشد، احساس میشود.
پردازش تمام نمونههای یک مجموعه کلان داده، ممکن است، تعداد قابل توجهی سرور را درگیر کند. بنابراین، هزینه سیستمها، بهازای هر واحد ذخیرهسازی، باید معقول و مقرونبهصرفه باشد.
ازنظر خرید مجوز نرمافزاری نیز، باید آنها مقرونبهصرفه باشند. زیرا ممکن است، روی تعداد قابل توجهی سرور نصب شوند.
علاوهبر این، سیستمها باید، هم در ذخیرهسازی داده و هم سختافزار مورداستفاده، دارای قابلیت توسعه پذیری باشند.
همچنین میبایست، روی سختافزارهای موجود و کمهزینه و عمومی قابل اجرا باشند، تا به کاهش هزینهها کمک کنند.
درنهایت، در چنین سیستمی، بهجای بردن دادهها به سمت پردازش، بایستی پردازش را به سمت دادهها برد.
اگر دادهها به صورت خطی پردازش شوند، شبکهها بهسرعت دچار کمبود پهنای باند خواهند شد.
سیستم کلان داده، نیازمند مجموعه ابزاری است که در عملکرد توانمند باشد. یک نوع پلتفرم ذخیرهسازی توزیعشده منحصربهفردی، که قادر به جابجایی حجم بسیار بالایی از دادهها، بدون از دست دادن آنها باشد.
ابزارها باید، شامل روشهایی برای پیکربندی یکسان، بهمنظور حفظ هماهنگی تمام سرورهای سیستم و همچنین راهحلهای یافتن داده و هدایت آن به سیستم باشند.
بهطور خلاصه، یک سیستم برای پردازش کلان داده نیازمند موارد زیر است،
روشی برای جمعآوری و طبقهبندی داده
و روشی برای جابهجایی داده در سیستم بهصورت ایمن، بدون از بین رفتن دادهها
و یک سیستم ذخیره که دارای مشخصات زیر است،
بین تعداد زیادی از سرورها توزیع شده باشد و قابل ارتقا به هزاران سرور باشد و قابلیت افزونگی داده و پشتیبان گیری داشته باشد و در موارد خرابی سختافزاری قابلیت بازیابی وجود داشته باشد و از لحاظ هزینه مقرونبهصرفه باشد.
و مجموعه ابزار کارآمد و پشتیبانی از کاربران
و روشی برای پیکربندی سیستم توزیعشده
و قابلیت پردازش موازی دادهها
و ابزارهای مانیتورینگ سیستم
و ابزارهای گزارشگیری
و ابزارهای ترجیحاً با رابط گرافیکی و کاربری آسان، بهمنظور ساختن وظایفی که داده را پردازش کرده و پیشرفت اجرای آنها را نمایش دهد.
و ابزارهای تعیین زمان، برای تعیین زمان اجرای وظایف و نمایش وضعیت آنها، توانایی مانیتورینگ روند دادهها، بهصورت آنی،
و بهمنظور کاهش پهنای باند مورد استفاده شبکه، پردازش محلی، در جاییکه داده، ذخیره میشود.
درحالیکه حجم دادهها در بسیاری از سازمانها ممکن است، بهحدی زیاد نباشد، که بتوان آنها را کلان داده اطلاق کرد، اما همه آنها، باید سیستمهای خود را بهعنوان یک کل، بررسی کنند.
یک سازمان بزرگ، ممکن است، دارای یک منبع دادهی بزرگ و مجزا باشد.
اگر سازمان شما بخواهد به عرصه کلان داده ورود کند، پیشاز هر چیز، این سوال، پیش میآید که چرا سازمان شما بایستی قواعد خود را تغییر دهد؟ چرایی نیاز به استفاده از کلان داده و دانستن رویکرد پردازش موازی در کلان دادهها را میتوان در پاسخ به نیازهای ذیل جستجو کرد.
اگر دادههایتان، دیگر توسط سیستمهای پایگاههای داده با رابط سنتی، قابل پردازش نیستند، احتمالا بدین معناست که دادههای سازمان، شما را در آینده، دچار مشکل خواهند کرد و ممکن است برای پردازش حجم بسیاری زیادی از دادهها در یک مدت زمان قابلقبول، تحت فشار قرار بگیرید.
همچنین یکی از بزرگترین هزینهها در ساخت یک سیستم کلان داده، نیاز به کارکنان متخصص برای نگهداری از آن و استفاده از دادههای موجود در آن است.
اگر از حالا شروع کنید، بهجای آنکه بعدها، مشاوران پرهزینه استخدام کنید، میتوانید یک مهارت و تخصص جدید را در سازمانهای خود شکوفا کنید.
دسترسی به این فناوریها و یادگیری آن، میتواند شما را یاری دهد، که یک شغل جدید و پرسود در عرصه کلان داده ایجاد کنید.
یک شرکت با پذیرش پلت فرمی که قابل ارتقا باشد، میتواند سقف حیات سیستم خود را گسترش داده و باعث ذخیرهی مالی شود.
یک شرکت که محدود به راهکارهای ناپایدار بود، ممکن است طی چند سال به ظرفیتی دست یابد، اما با گذر زمان نیازمند توسعه مجدد میباشد.
چنانچه یک شرکت هماکنون در زمینههای کلان داده فعال شود، میتواند آینده خود را تضمین کرده و ریسکها را کاهش دهد.
هنگام پیادهسازی هر سیستم کلان داده، سازمان شما باید اهدافش را بهخاطر داشته باشد.
چرا سیستم خود را ارتقا میدهید؟
به چه امیدی این کار را انجام میدهید؟
چگونه سیستم کارآمد خواهد بود؟
چه چیزی را ذخیره میکنید؟
چالشهای امنیت زیرساخت و حریم خصوصی اطلاعات و دادهها را میتوان از چهار جنبه بررسی کرد،
امنیت زیرساخت
حریم خصوصی اطلاعات و دادهها
مدیریت دادهها
امنیت یکپارچگی
در این خلاصه کوتاه، مفهوم کلان داده را بحث نموده و به معرفی چالشها، پتانسیلها و مزایای کلان داده پرداخته و یک مجموعه از نیازمندیها را برای ایجاد یک سیستم کلان داده ساختیافته، نیمه ساختیافته و غیر ساختیافته، بررسی کردیم.
لطفا برای جلوگیری از قطع درختان، به جز موارد بسیار ضروری، ازچاپ روی کاغذ، خودداری فرمایید.
غنی سازی برای کار آفرینی و مدیریت با استفاده از فناوری اطلاعات و ارتباطات
